
Intellicast S3E40 – Talking Cannabis Research with Arundati Dandapani of Generation1.ca
August 25, 2020Intellicast S3E41 – Mental Wellbeing in Research, New Partnerships, and More MR News
September 1, 2020
Brand awareness is something we consistently evaluate in our research-on-research. We know that it varies across panels and respondents, but how is brand awareness affected and what can it tell us about our data quality?
In this blog, we are taking a deeper dive into the brand awareness question we asked in our 2020 Research-on-Research report.
Two of the brands we asked about, Coke and McDonald’s, are brands known across the globe. However, 12% of respondents claimed to be unaware of McDonald’s and 14% of respondents claimed to be unaware of Coke
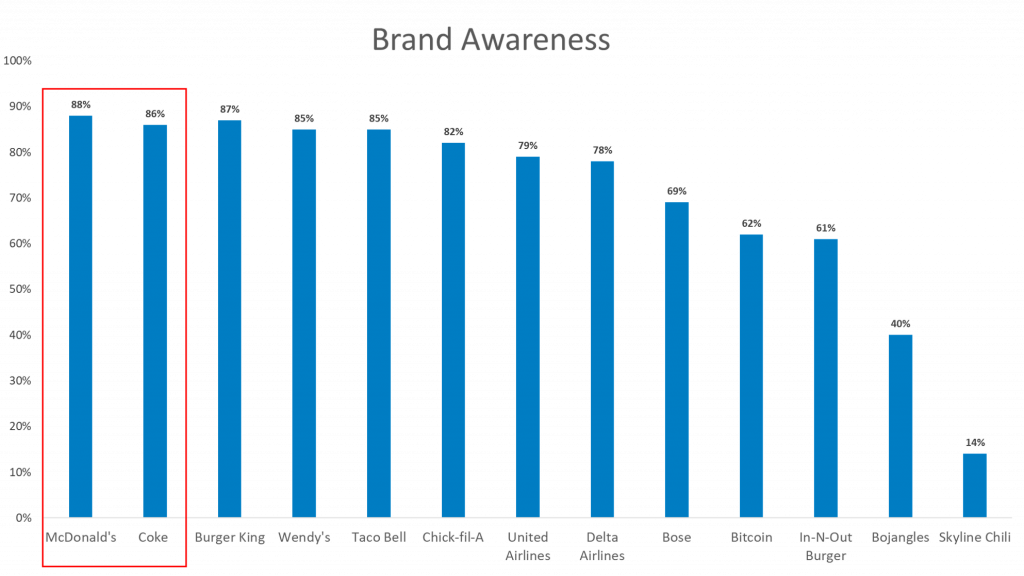
Since there was a percentage of respondents that said they were unaware of these brands, we added a follow-up question to probe on this further. We asked those respondents if they made a mistake and actually are aware of the brand, if they just didn’t want any more questions about the brand, or if they are truly unaware of the brand.
For both brands, around 30% of respondents who said they were not aware of the brands claimed to actually be unaware of the brands when we asked them again.
Of the respondents that claimed they are truly unaware of the brands, you can see that the number of failed data quality checks increases.
Of the respondents that failed 5 or more data quality checks, 48% claimed they are truly unaware of the Coke Brand and 46% claimed they are truly unaware of the McDonald’s Brand.
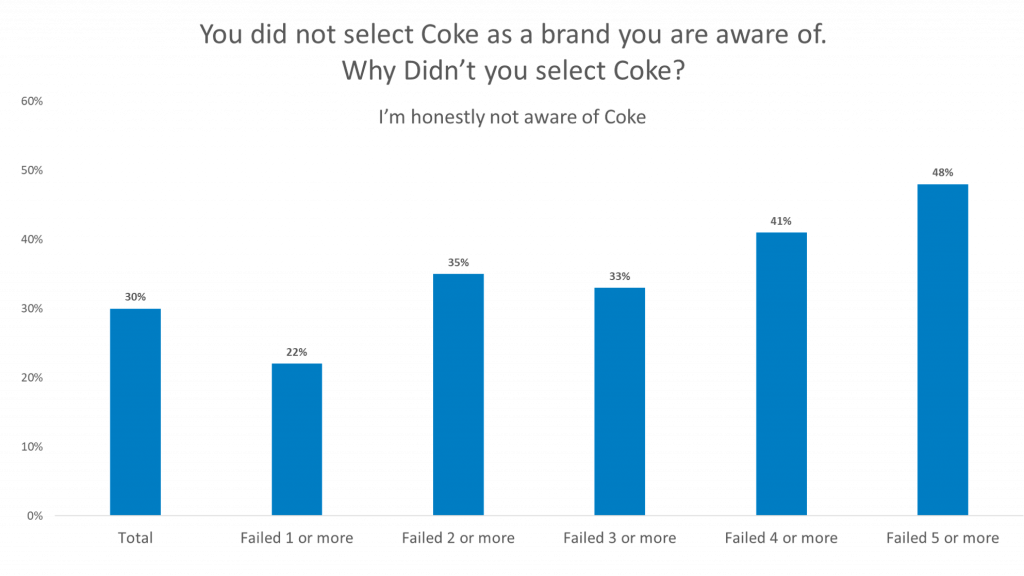
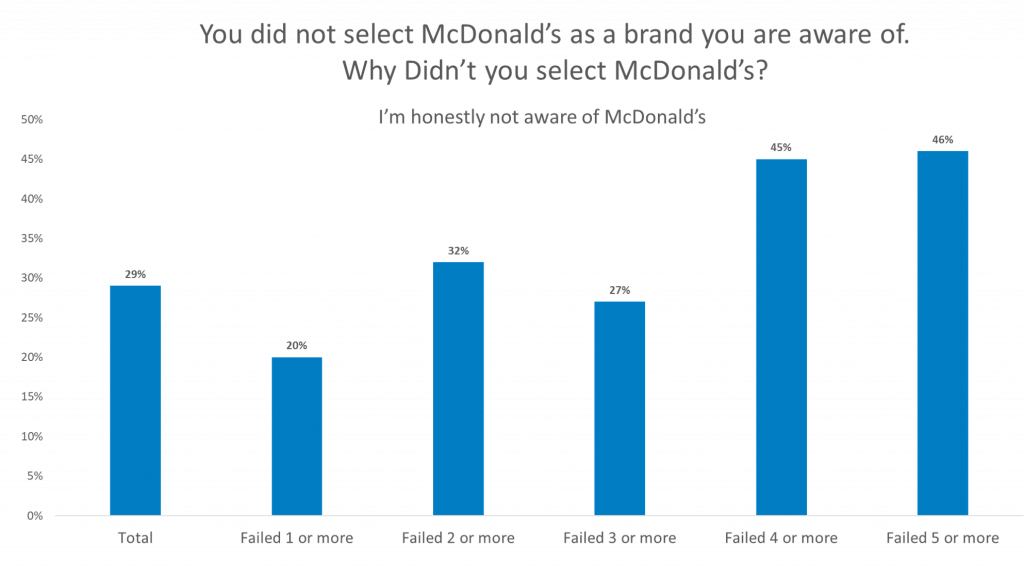
If we were to remove the respondents that failed the most data quality checks—the least reliable respondents—the number of truly unaware respondents would greatly decrease.
The more “bad respondents” we include, the more the data is overestimated.
Some respondents also gave reasoning for why they claimed they were unaware of Coke initially. Some said they misinterpreted the question, not realizing that even though they may not drink Coke products, they can still be aware of the brand. This confusion also contributes to the overestimate of the number of respondents who are “unaware” of the Coke Brand.
For example, some open-end responses are:
- “I’m aware, I just don’t drink or use this product.”
- “Don’t drink Coke.”
- “I do not drink soda.”
- “I don’t drink any pop.”
The same can be said for McDonald’s.
- “Confused about brands or restaurants.”
- “I did not eat outside.”
- “I wasn’t paying attention.”
Overall, the respondents that are swaying the data also tend to be the least reliable respondents—the biggest outliers are the biggest offenders.
If we were to take out the biggest offenders/least reliable respondents, the number of respondents that claimed they are truly unaware of the two brands would greatly decrease. This makes more sense because it is very unlikely that someone would be unaware of these two brands.
To read more about data quality, check out our Data Quality series! Follow these links to learn more:
An Introduction to Data Quality Checks and Their Use Determining Data Quality
When It Comes to Data Quality—Not All Panels are Equal
Data Quality—Demographic Differences
Changes in Attitudes and Behaviors and How they Impact Data Quality
What Open Ends Can Tell You About Data Quality
Recommendations and Best Practices for Improved Data Quality



{kind=link}
{kind=link}
{kind=link}